Click here to access Github repo containing relevant code or continue reading below on for non-technical description of the project.
Technologies/Skills Used
Problem Description
English language learners require timely and accurate feedback on essays in order to measure progress towards fluency. Ideally, students receive constructive feedback indicating which particular areas require greater focus. Manually grading essays with comprehensive rubrics with multiple traits, however, is a laborious process that prevents timely evaluation and is subject to bias and grader fatigue.
Data & Performance Metric
Several foundations, in conjunction with Vanderbilt University and the educational non-profit The Learning Agency Lab, published the ELLIPSE dataset via Kaggle in 2022. Students wrote argumentative essays in response to a variety of different prompts, setting up a cross-prompt multi-trait AES scoring task. According to the Learning Agency Lab, the ELLIPSE corpus “comprises 3911 argumentative essays written by 8th-12th grade ELLs. The essays were scored according to six analytic measures: cohesion, syntax, vocabulary, phraseology, grammar, and conventions…each measure represents a component of proficiency in essay writing, with greater scores corresponding to greater proficiency in that measure. The scores range from 1.0 to 5.0 in increments of 0.5.” Performance we measured by lowest mean column-wise root mean squared error (MCRMSE). Below are some short excerpts from selected essays.
Experiments
After preprocessing our text inputs and selecting a performance metric, we developed three families of models:
- Baseline experiments that relied on handcrafted features created using spaCy
- The most performant BERT and DeBERTa models that were fine-tuned for our particular task
- Additional BERT and DeBERTa models that were used to illustrate alternative approaches
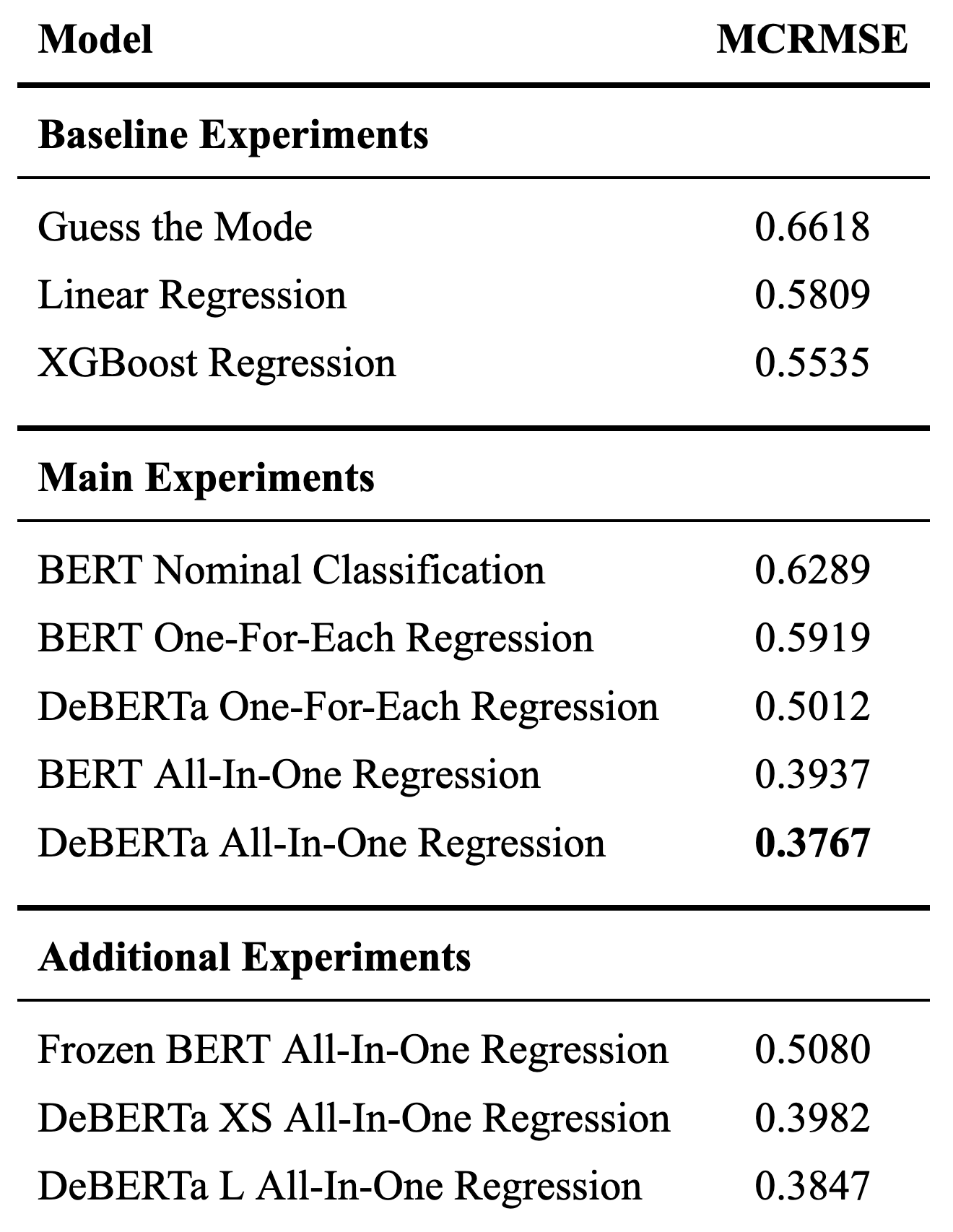
A table of the baseline models, subsequent transformer-based models, and accompanying MCRMSE for the final, held-out test sets run with the same number of epochs and batch size follow below. All DeBERTa models employed DeBERTaV3
Results
The source of greatest progress came from “going all-in” with DeBERTa All-In-One Regression, as evidenced by its 0.3767 MCRMSE. Contrary to the one-for-each models where models were trained in parallel for each rubric trait, these all-in-one models predicted all six traits at once from the same network with a simple six node regression dense layer. Since essays that scored well in cohesion also tended to score highly in vocabulary, we hypothesize that the all-in-one models tended to perform better because one trait is highly predictive of another such that mutually reinforcing or shared signals propagate through a shared architecture, boosting performance. For example, an essay with excellent cohesion is also likely to have advanced vocabulary, and thus feedback to improve vocabulary performance would also improve that of cohesion and performance and vice versa.
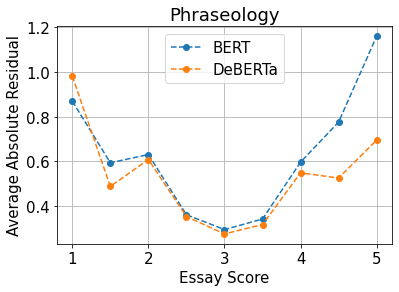
One hypothesis for why DeBERTa is better able to score phraseology in general is due to its enhanced mask decoder in which both absolute and relative positions of the words are taken into account instead of just the absolute position embeddings that BERT monitors. BERT’s strategy of using the absolute position vectors in the input layer hinders the ability for the BERT model to appropriately learn information regarding relative positions. DeBERTa incorporates absolute position vectors after the transformer blocks and before the softmax layer for the predicting masked tokens. In doing this, DeBERTa gathers the relative position information from all transformer blocks and only uses absolute position as complimentary information when predicting masked words. This understanding of relational position is critical in assessing the phraseology rubric. Lexicon bundles, a component of phraseology, is a prime example of why DeBERTa can assess how these words are used in relation to one another.
Conclusion
Experiments using all-in-one and one-for-each architectures with both BERT and DeBERTa demonstrate that the most performant approach is to use an all-in-one DeBERTa regression model to predict scores for multi-trait essays written by high school ELLs. Meaningful hyperparameter considerations include fine-tuning DeBERTa on the training set and using small batch sizes.
Paper was completed by Kurt Eulau, Alex Carite, and Tom Welsh. Please contact Kurt Eulau for a copy of the full paper.